Advanced referencing
I want to build an AI-assisted tool that can summarize the content of a document and able to referencing back to the sources with citation of exact page. I’m using Azure Document intelligence with Azure AI Search to conduct the experiment.
What are the tasks
- Data chunking: determine the best strategy for breaking documents into meaningful units for accurate referencing.
- Bounding box of reference: enable visual traceability of references in the UI.
- LLM based citation with human review: embedding citations in the system prompts and using a separate citation service
Data chunking
There are different techniques that can be used for data chunking.
Common Chunking Strategies for RAG
- Fixed-Size Chunking
- Description: Splits text into uniform chunks based on a set number of tokens, characters, or words, regardless of document structure.
- Pros: Simple to implement and computationally efficient. Predictable chunk sizes, which can be tuned to fit model input limits. Works well for homogeneous, unstructured datasets.
- Cons: May break sentences or ideas mid-way, leading to incoherent chunks and loss of context. Makes precise citation (e.g., to a specific line) harder, as chunk boundaries rarely align with logical document divisions. Can result in fragmented retrieval and less relevant outputs, especially for structured documents.
- Sentence-Based Chunking
- Description: Each chunk consists of one or more complete sentences.
- Pros: Maintains semantic integrity—chunks are less likely to split ideas.
- Good for tasks needing precise, granular retrieval (e.g., fact-checking). Easier to map retrieved content back to specific lines or sentences for citation.
- Cons: May produce too many small chunks, increasing retrieval and processing overhead5. Short sentences may lack sufficient context for meaningful retrieval.
- Paragraph-Based Chunking
- Description: Chunks align with paragraph boundaries.
- Pros:Preserves logical structure and context, especially in well-structured documents. Chunks are typically large enough to capture context but small enough for efficient retrieval. Easier to cite at the paragraph or line level, especially if paragraph/line metadata is retained.
- Cons:Paragraphs can vary greatly in length, leading to inconsistent chunk sizes. Long paragraphs may exceed model input limits and require further splitting.
- Line-Based Chunking
- Description: Each line is treated as a chunk.
- Pros:Maximum citation granularity—retrieved information can be mapped directly to a specific line. Useful for highly structured documents (e.g., code, legal texts) where line-level referencing is needed.
- Cons:Lines are often too short to provide meaningful context, reducing retrieval accuracy. Can dramatically increase the number of chunks, impacting performance and storage.
- Recursive/Hierarchical Chunking
- Description: Splits text using a hierarchy of separators (section → paragraph → sentence → line), recursively breaking down large units until desired chunk size or structure is achieved.
- Pros:Preserves logical and semantic boundaries, adapting to document structure. Flexible—can be tailored to ensure chunks fit both context and model input limits. Facilitates precise citations by maintaining a mapping from chunk to section/paragraph/line.
- Cons:More complex to implement. Requires careful tuning to avoid over- or under-chunking2.
- Semantic Chunking
- Description: Uses NLP techniques to split text into chunks that represent coherent ideas or topics, regardless of physical boundaries.
- Pros:Maximizes retrieval relevance—each chunk is a self-contained, meaningful unit. Enhances embedding quality and system interpretability. Reduces noise and improves context for the generator.
- Cons:Computationally intensive and slower to process. May not always outperform simpler methods, especially for highly structured content. Difficult to map directly to specific lines for citation unless line metadata is preserved.
- Overlapping (Sliding Window) Chunking
- Description: Chunks overlap by a certain number of tokens, sentences, or lines to preserve context at the boundaries843.
- Pros:Reduces information loss at chunk edges, improving retrieval quality. Enhances context continuity, especially for queries that span chunk boundaries.
- Cons:Increases storage and retrieval redundancy. Can complicate citation, as the same line may appear in multiple chunks.
- Document-Specific/Structural Chunking
- Description: Chunks are defined by the document’s logical structure (sections, subsections, paragraphs, lines), often with metadata for each chunk.
- Pros:Preserves author’s intended organization. Facilitates precise citation and traceability. Especially effective for structured documents (e.g., legal, technical, academic).
- Cons:May require custom logic for different document types. Chunk sizes can be inconsistent, sometimes requiring further splitting.
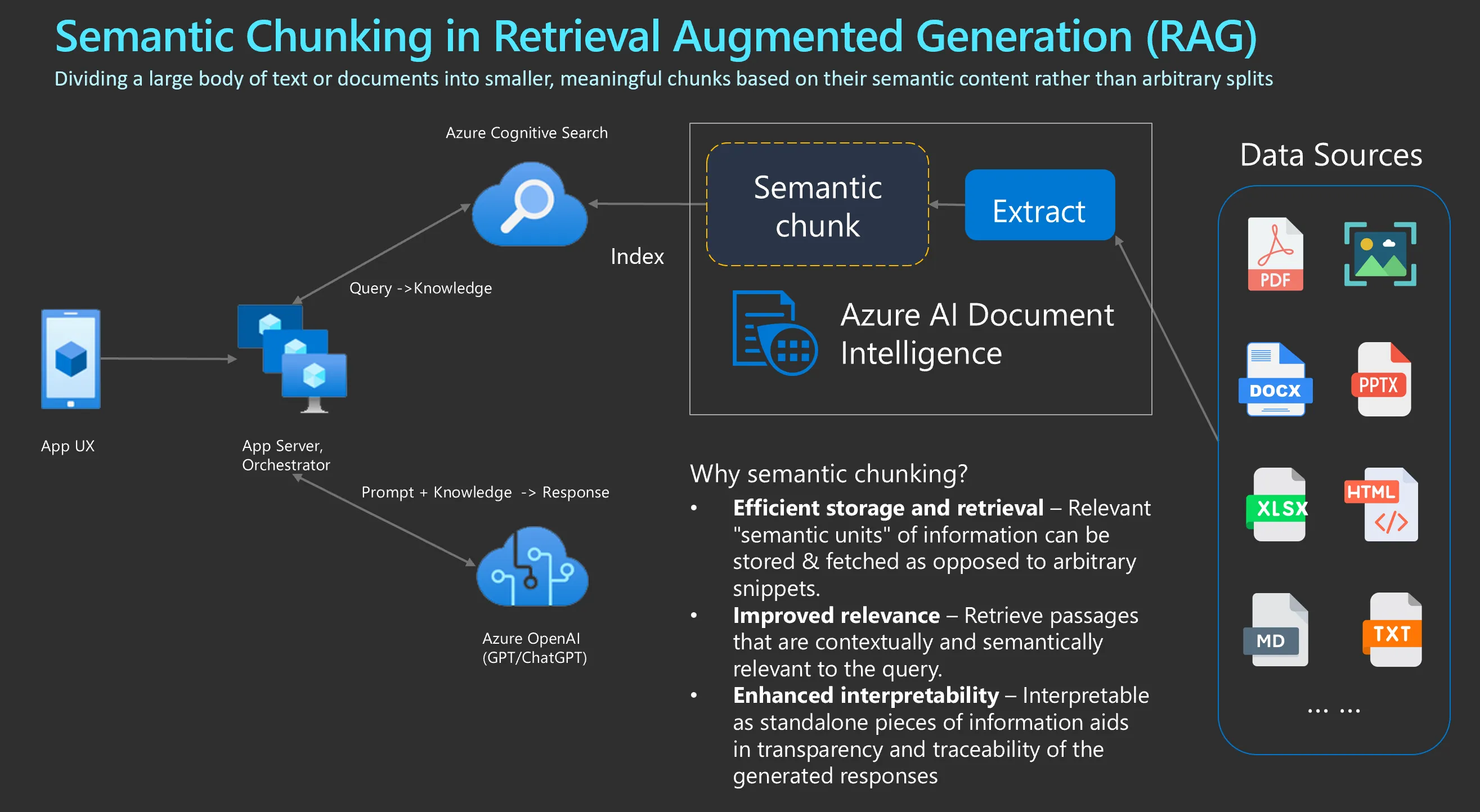
Semantic chunking in RAG
Semantic chunking considers the relationships within the text. It divides the text into meaningful, semantically complete chunks. It involves taking the embeddings of every sentence in the document, comparing the similarity of all sentences with each other and then grouping sentences with the most similar embeddings together.
Why semantic chunking
- efficient storage and retrieval: relevant semantic unit of information can be stored and fetched as opposed to arbitrary snippets
- improved relevance: retrieve passages that are contextually and semantically relevant to the query
- enhanced interpretability: interpretable as standalone pieces of information aids in transparency and traceability of generated responses
Prerequisite Components
Using AI document as document loader, which can extract tables, paragaphs and layout information from data source (pdf, png,…) The output markdown then be used in Langchain markdown header splitter, which enables the semantic chunking of the documents then the chunked documents are indexed into AI search vector store. Given user query, use AI search to get the relevant chunks then feed the context into the prompt with the query to generate the answer.
- Azure Document Intelligence: as document loader, extract the layout from data source
- Azure AI search: as indexer to convert markdown to vector
- Azure OpenAI: given the prompt and knowledge from the AI search to answer the question

Execution
- Initiate Azure AI Document Intelligence to load the document
loader = AzureAIDocumentIntelligenceLoader(file_path=<file-path>, api_key = doc_intelligence_key, api_endpoint = doc_intelligence_endpoint, api_model="prebuilt-layout")
docs = loader.load()
- Split the document into pages based on the
<!--PageBreak-->
pages = docs[0].page_content.split("<!-- PageBreak -->")
- Split the document into chunks based on the markdown headers
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
- Construct the metadata includes the content, page number and chunk id
splits_with_metadata = []
for i, page_text in enumerate(pages):
splits = text_splitter.split_text(page_text)
for split in splits:
split.metadata["page_number"] = i+1
split.metadata["chunk_id"] = f"page-{i+1}-chunk-{len(splits_with_metadata)}"
splits_with_metadata.append(split)
print(f"Total chunks: {len(splits_with_metadata)}")
- Embed the documents and insert into AZ Search vector store
# Note: The vector_search_dimensions should match your embedding model:
# - text-embedding-ada-002: 1536 dimensions
# - text-embedding-3-small: 1536 dimensions
# - text-embedding-3-large: 3072 dimensions
# Embed the splitted documents and insert into Azure Search vector store
aoai_embeddings = AzureOpenAIEmbeddings(
azure_deployment="text-embedding-ada-002"
)
vector_store_address: str = os.getenv("AZURE_SEARCH_ENDPOINT")
vector_store_password: str = os.getenv("AZURE_SEARCH_ADMIN_KEY")
index_name: str = "azureblob-indexer"
# Configure vector search settings for Azure AI Search
from azure.search.documents.indexes.models import (
SearchIndex,
SearchField,
SearchFieldDataType,
SimpleField,
SearchableField,
VectorSearch,
HnswAlgorithmConfiguration,
VectorSearchProfile,
SemanticConfiguration,
SemanticSearch,
SemanticPrioritizedFields,
SemanticField
)
vector_profile="vector-profile-1751892888721"
algo_config="vector-config-1751892889955"
# Define the vector search configuration
vector_search = VectorSearch(
profiles=[
VectorSearchProfile(
name=vector_profile,
algorithm_configuration_name=algo_config,
)
],
algorithms=[
HnswAlgorithmConfiguration(
name=algo_config
)
],
)
# Define the semantic search configuration
semantic_config = SemanticConfiguration(
name="my-semantic-config",
prioritized_fields=SemanticPrioritizedFields(
content_fields=[SemanticField(field_name="content")]
),
)
semantic_search = SemanticSearch(configurations=[semantic_config])
# Define the search fields
fields = [
SimpleField(
name="id",
type=SearchFieldDataType.String,
key=True,
filterable=True,
),
SearchableField(
name="content",
type=SearchFieldDataType.String,
searchable=True,
),
SearchField(
name="content_vector",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=1536, # Adjust based on your embedding model
vector_search_profile_name=vector_profile,
),
SearchableField(
name="metadata",
type=SearchFieldDataType.String,
searchable=True,
),
]
vector_store: AzureSearch = AzureSearch(
azure_search_endpoint=vector_store_address,
azure_search_key=vector_store_password,
index_name=index_name,
embedding_function=aoai_embeddings.embed_query,
fields=fields,
vector_search=vector_search,
semantic_configuration_name="my-semantic-config",
semantic_search=semantic_search,
)
vector_store.add_documents(documents=splits_with_metadata)
- Retrieve the data
a. retrieve the relevant chunks based on a question
retriever = vector_store.as_retriever(search_type="similarity", k=5)
retrieved_docs = retriever.get_relevant_documents(
<your-question>
)
b. retrieve the documents based on vector similarity (with relevance score)
docs_and_scores = vector_store.similarity_search_with_relevance_scores(
query=<your-question>,
k=5,
score_threshold=0.80,
)
c. retrieve the documents with hybrid search
docs = vector_store.similarity_search(
query=<your-question>,
k=3,
search_type="hybrid",
)
- Document Q&A with reference
prompt = PromptTemplate.from_template(
"""
You are a helpful assistant. Use the context below to answer the question.
For each fact you use, add a citation like: [source:{source}, page:{page_number}].
Context:
{context}
Question: {question}
Answer:
"""
)
llm = AzureChatOpenAI(
openai_api_version="2024-12-01-preview",
azure_deployment="gpt-4.1",
temperature=0,
)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke(<your-question>)
rag_chain_from_docs = (
{
"context": lambda input: format_docs(input["documents"]),
"question": itemgetter("question"),
}
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableMap(
{"documents": retriever, "question": RunnablePassthrough()}
) | {
"documents": lambda input: [doc.metadata for doc in input["documents"]],
"answer": rag_chain_from_docs,
}
rag_chain_with_source.invoke(<your-question>)
 8. Bounding box
8. Bounding box